Aprendizado não-supervisionado¶
Autor: Felipe Maia Polo - Fundador e ex-presidente do Neuron - Data science and Artificial Intelligence, economista pela USP e mestrando em Estatística pela mesma instituição. Apaixonado por matemática, estatística e data science.
Contato: felipemaiapolo@gmail.com - https://www.linkedin.com/in/felipemaiapolo/
Feedback: https://forms.gle/U6yBVSYwxNRWaE15A
Sugestões de leitura
- Probabilidade: Ross, S. (2014). A first course in probability. Pearson.
- Probabilidade e Estatística: Morettin, P. A., & BUSSAB, W. O. (2017). Estatística básica. Editora Saraiva.
- Análise de Regressão (linear & logística): Wooldridge, J. M. (2015). Introductory econometrics: A modern approach. Nelson Education.
- Machine Learning: James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An introduction to statistical learning (Vol. 112, p. 18). New York: springer.
Nos momentos em que falamos em Machine Learning até agora, excluindo a parte do PCA, focamos nossos esforços para o entedimentos das técnicas de Aprendizado Supervisionado, que é quando temos uma variável resposta $Y$ e queremos que a máquina aprenda uma função $f(.)$ que nos ajude a prever $Y$ com base em uma matriz de atributos (features) $X$. Por exemplo, quando queríamos prever o preços dos imóveis, $Y$ era o preço (já dado em nossa base), $X$ era uma matriz com as informações de cada imóvel (uma linha por imóvel, sendo que as colunas eram os atributos) e $f(.)$ uma função regressora, ou regressor, estimada por uma Rede Neural. Já no caso das consultas médicas, $Y$ era uma variável indicadora (0 ou 1) que nos dizia se o paciente foi ou não à consulta, $X$ eram atributos tanto do paciente quanto do agendamento e $f(.)$, mais uma vez, uma função classificadora, ou simplesmente classificador, aprendida por uma Rede Neural.
Perceba que quando utilizamos a técnica dos Componentes Principais para a redução de dimensionalidade, não existia nenhuma variável "$Y$" que gostaríamos de prever - tudo o que dispunhamos era $X$, sendo que queríamos representar essa matriz em uma menor dimensão. Pelo motivo de não existir uma variável de interesse "$Y$" ao aplicar este modelo, dizemos que o PCA é uma técnica de aprendizado não-supervisionada. Nesta parte do curso, vamos ver uma outra técnica para redução de dimensionalidade e focar nossas atenções na técnica $K-Means$, um modelo muito importante e que é capaz de descobrir estruturas escondidas nos dados. Essa técnica é um modelo de clusterização, ou segmentação, e é utilizada para agruparmos indivíduos diferentes em nossa base de dados. Mas por que isso é importante? É importante pois poderemos entender melhor nossos clientes e nos direcionar mais objetivamente a cada um dos grupos.
A partir de agora vamos trabalhar com uma base de dados de clientes de um shopping. Essa base de dados foi retirada do Kaggle (https://www.kaggle.com/vjchoudhary7/customer-segmentation-tutorial-in-python), conta com 200 clientes, sendo que temos 4 características de cada um deles dada pelas variáveis:
- CustomerID: ID único de cada cliente
- Gender: Gênero (Feminino ou Masculino)
- Age: Idade do cliente
- Annual Income: Renda anual do cliente (em mil dólares)
- Spending Score (1-100): Pontuação criada pelo shopping com base nos comportamentos de consumo
Vamos aos trabalhos!? Vamos começar chamando os pacotes que utilizaremos:
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from IPython.display import Image
from IPython.core.display import HTML
import matplotlib.pyplot as plt
Abrindo a base de dados:
data = pd.read_csv('shopping_data.csv') #importando o dataset
Checando o formato da base de dados:
data.shape
Checando os dados com .head():
data.head()
Para facilitar a manipulação da nossa base de dados, vamos transformar a variável Gênero em binária, sendo que o gênero feminino será representado por 1 e o masculino por 0:
def genero(x):
if x == 'Female':
return 1
else:
return 0
data['Genre'] = data['Genre'].apply(genero)
data.head()
O modelo de agrupamento (K-Means) que utilizaremos funciona bem somente com variáveis quantitativas, então não utilizaremos a variável de gênero para realizar o agrupamento - deixarei alguns links caso queiram utilizar variáveis qualitativas no agrupamento:
- https://www.quora.com/Can-a-binary-categorical-variable-be-used-in-K-means-clustering
- https://www-01.ibm.com/support/docview.wss?uid=swg21477401
- https://stats.stackexchange.com/questions/130974/how-to-use-both-binary-and-continuous-variables-together-in-clustering
Como não utilizaremos nem a variável de gênero e nem a variável de Id no momento do agrupamento, vamos criar uma base de dados auxiliar somente com as variáveis que queremos. Preste atenção que este momento é muito importante, pois devemos verificar se alguma das variáveis que utilizaremos tem valores faltantes e, se tiverem, deveremos manter somente aqueles indivíduos que não têm valores faltantes em nenhuma das variáveis. Vamos checar com a função describe():
data.describe()
É possível ver que todas as variáveis têm "count" igual a 200, que é o número de linhas na base, então não temos valores faltantes, dado que o dataset está bem formatado e poderíamos fazer a identificação deste maneira. Criando nossa base auxiliar somente com as variáveis de interesse:
temp=data.copy(deep=True)
temp.drop(["CustomerID"],axis=1,inplace= True)
temp.drop(["Genre"],axis=1,inplace= True)
Antes de realizar o agrupamente, faremos uma normalização nos dados, pois dados com escalas diferentes podem influenciar/viesar nossos resultados. Para isso, utilizaremos a normalização entre 0 e 1, que já foi vista:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(temp)
#transformando
temp=scaler.transform(temp)
Perceba que aqui não fizemos uma divisão entre base de treino e teste, pois não é muito comum agir dessa maneira quando nosso fim é o agrupamento, mesmo que existam algumas abordagens em que isso possa ser feito. Uma maneira de sabermos mais ou menos como nossos dados podem se agrupar é utilizando a técnica TSNE, que é uma técnica de redução de dimensionalidade. Diferentemente do PCA, esta técnica foi criada com o intuito de se manter a estrutura de distâncias presentes nos dados originais. Sendo assim, ela consegue manter muito bem a estrutura de agrupamento entre os indivíduos. Vamos utilizar esta técnica somente para tentar visualizar, em duas dimensões, como nosso modelo K-Means provavelmente fará as divisões de clusters:
import numpy as np
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=42).fit_transform(temp)
plt.plot(tsne[:,0],tsne[:,1], 'bo')
plt.show()

Na figura acima é possível ver que há algumas maneiras de se agrupar os indivíduos, sendo elas mais ou menos claras.
Agora vamos passar da etapa mais visual de identificação para a parte algoritmica, que é quando vamos identificar clusters nos nossos dados com o auxílio do modelo K-Means. Como todo modelo de Machine Learning, o K-Means tenta minimizar alguma função de erro dado o número de clusters $K$ escolhido pelo cientista de dados, ou seja, $K$ é um hiperparâmetro. A função de erro em questão se chama WCSS (Within Cluster Sum of Squares) e ela nos dá uma a soma dos erros quadráticos cometidos por cada indivíduo de cada um dos clusters.
Para ficar mais claro, vamos de exemplo. Suponha que em nossos dados tenhamos dois clusters, como na figura abaixo:
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=300, centers=2, n_features=2, random_state=42)
plt.scatter(X[:,0],X[:,1])
plt.show()

É visível a divisão que pode ser feita, vamos fazê-la então:
plt.scatter(X[:,0],X[:,1], c = y)
plt.show()

O primeiro passo para computar o erro WCSS é achar o centro (centróide) de cada um dos clusters. Vamos chamar o cluster da esqueda de cluster 0 e o cluster de direita de cluster 1 e agora vamos calcular seus centros (centróides), que são dados pelas médias de todos os pontos que fazem parte daquele cluster:
c0=np.mean(X[y==0], axis=0)
c1=np.mean(X[y==1], axis=0)
c0,c1
Para calcular o erro WCSS basta calcular a distância euclidiana ao quadrado entre todos os pontos e o seu repectivo centróide e somar tudo. A distância euclidiana, e o seu quadrado, entre um ponto $x=(x_1,x_2)$ e outro ponto $y=(y_1,y_2)$ são dadas pelas seguintes fórmulas:
\begin{equation} d(x,y)=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2} \Rightarrow d^2(x,y)=(x_1-y_1)^2+(x_2-y_2)^2 \end{equation}Vamos calcular o erro WCSS para esse nosso exemplo:
WCSS0=np.sum((X[y==0]-c0)**2)
WCSS1=np.sum((X[y==1]-c1)**2)
WCSS=WCSS0+WCSS1
print("O erro WCSS cometido pela clusterização do exemplo é ", WCSS)
Perceba que na conta acima, calculei o erro WCSS para cada cluster separadamente e depois somei tudo. Essa configuração de cluster que criamos é a que minimiza o erro WCSS dada a quantidade de 2 clusters. Vamos fazer algumas mudanças em $y$ para você ver uma configuração de cluster que não é boa - vamos forçar os 50 primeiros indivíduos a serem do cluster 0 e os 50 últimos a serem do cluster 1:
y[:50]=0
y[250:]=1
Vamos plotar novamente os clusters:
plt.scatter(X[:,0],X[:,1], c = y)
plt.show()

Parece que a divisão feita agora não foi muito inteligente. Vamos verificar isso pelo erro WCSS:
c0=np.mean(X[y==0], axis=0)
c1=np.mean(X[y==1], axis=0)
WCSS0=np.sum((X[y==0]-c0)**2)
WCSS1=np.sum((X[y==1]-c1)**2)
WCSS=WCSS0+WCSS1
print("O erro WSCC cometido pela clusterização do exemplo é ", WCSS)
É possível ver que se a divisão não for bem feita, e erro tende a ser muito alto. Para a aplicação do modelo K-Means, basta dizer quantos clusters você quer encontrar nos dados e ele fará uma divisão de forma a minimizar o erro WCSS (nem sempre ele chega na melhor divisão possível, mas quase sempre chega a um resultado satisfatório). No exemplo acima já começamos com o vetor $y$ que indicava a que cluster pertencia o indivíduo, mas na vida real, começaremos somente com $X$ e o modelo K-Means nos retornará $y$. A clusterização pega dados sem rótulos e rotula cada um de seus indivíduos da seguinte maneira:
Image(url= "p7.png", width=700, height=300)
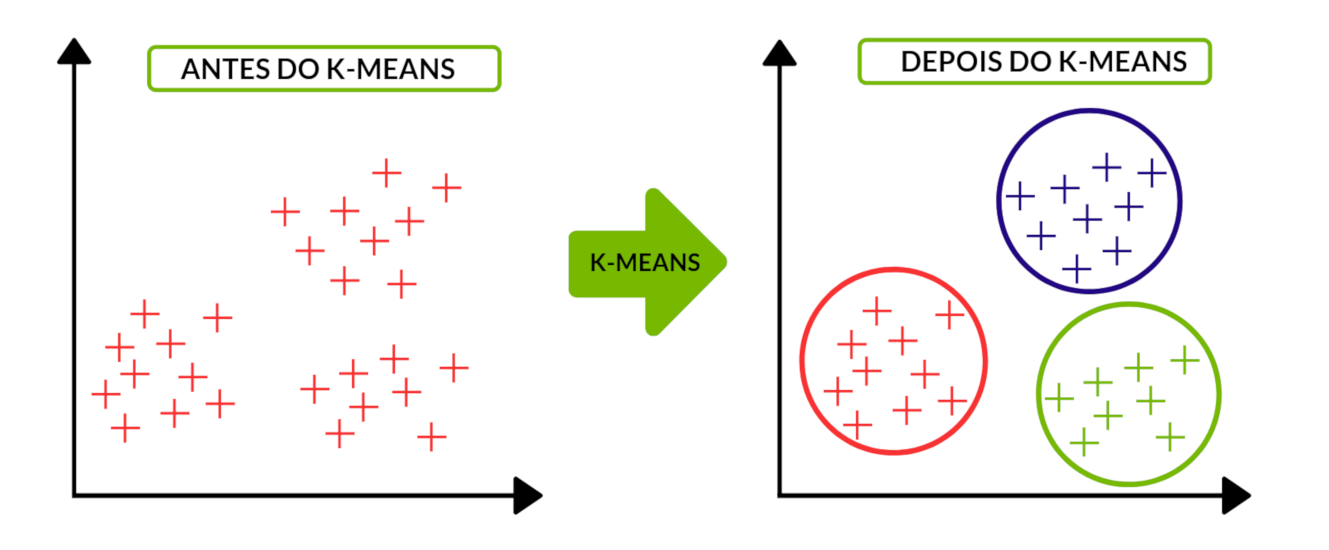
Adaptado de: https://cdn-images-1.medium.com/max/1600/1*tWaaZX75oumVwBMcKN-eHA.png
{kind=link}
Agora vamos aplicar o modelo K-Means para achar exatamente 3 clusters em nossos dados (só para teste):
kmeans = KMeans(n_clusters = 3, random_state=42)
kmeans.fit(temp)
cluster_labels = kmeans.predict(temp) #Pegando os rótulos
Agora que já dividimos nossa base em dois clusters, vamos fazer a visualização com as variáveis geradas pelo TSNE:
plt.scatter(tsne[:,0], tsne[:,1], c = kmeans.labels_)
plt.title('Visualização dos Clusters em duas dimensões (TSNE)')
plt.show()

Com três clusters conseguimos um resultado razoável. Mas como fazer a otimização do número de clusters!? Existe a medida de se chama Silhueta Média (https://en.wikipedia.org/wiki/Silhouette_(clustering)). Essa medida varia de -1 a 1 e quanto mais próximo de 1, mais coesos serão os clusters formados. Vamos rodar o K-Means para vários números de clusters e descobrir qual aquele com a melhor Silhueta Média:
sill = []
for i in range(2, 15):
kmeans = KMeans(n_clusters = i, random_state=0)
kmeans.fit(temp)
cluster_labels = kmeans.predict(temp)
sill.append(silhouette_score(temp, cluster_labels))
plt.plot(range(2, 15), sill)
plt.title('O Método da Silhueta')
plt.xlabel('Némero de Clusters')
plt.ylabel('Silhueta média')
plt.show()

É possível ver que o número de Clusters que maximiza a silhueta média é de 9 clusters, MAS perceba que o valor da silhueta média não difere significantemente de quando temos 6 clusters. Como sempre tentamos optar pelo modelo mais simples e que traga uma boa representação da realidade, vamos optar por ficar com 6 clusters ao invés de 9, mesmo que $K=6$ não maximize a silhueta média em nossos dados - veja que o resultado é muito parecido e que não valeria a pena tornar o modelo ainda mais complexo. Veja que esse é um julgamento muito subjetivo e só reforça a ideia de que quem decide no final do dia número de clusters é o cientista de dados e não o computador - é importante também descrever cada um dos clusters formados, checando se o resultado faz algum sentido teórico. Descrever os clusters e tentar contar uma história com base nos dados também deve te ajudar a escolher o número de clusters que serão formados. Preste atenção que quando estamos trabalhando com aprendizado não-supervisionado, a avaliação do modelo é um pouco mais complicada e menos objetiva. Vamos então formar 6 clusters:
kmeans = KMeans(n_clusters = 6, random_state=0)
kmeans.fit(temp)
plt.scatter(tsne[:,0], tsne[:,1], c = kmeans.labels_)
plt.title('Visualização dos Clusters em duas dimensões (TSNE)')
plt.show()

Agora nos resta descrever os clusters com base em suas características. Vamos aqui descrever dois dos clusters formados, o 0 e o 1:
labels = pd.DataFrame(kmeans.predict(temp))
labels.columns = ['Cluster']
data=pd.merge(data,labels, left_index=True, right_index=True)
Descrevendo o Cluster 0:
data[data.loc[:,"Cluster"]==0].describe()
Descrevendo o Cluster 1:
data[data.loc[:,"Cluster"]==1].describe()